



Generative AI has marked significant progress in AI. Yet, in enterprises, discriminative AI remains predominant due to its direct relevance to solving practical business issues — and that applies to ecommerce too.
Additionally, unsupervised learning, especially clustering, keeps offering valuable insights. So while generative AI is real hot, discriminative models and clustering continue to deliver concrete business value, maintaining their essential role in enterprise AI. Let’s dig into each.
In a nutshell, these techniques use machine learning (ML) to group information. But the devil is in the details-while they do share a common goal, we can’t overlook their major differences.
Why the interest, you might ask? Analysts expect that artificial intelligence will power 95% of customer interactions by 2025. While it may unlock business opportunities and drive ecommerce growth with intelligent product recommendations, query suggestions, and personalized experiences, AI remains a vague and intimidating phrase for many.
Let’s look at clustering vs classification from an ecommerce perspective, with some real-world use cases and examples.
What Is the Difference Between Classification and Clustering?
Classification sorts data into specific categories using a labeled dataset. Clustering is partitioning an unlabeled dataset into groups of similar objects.
Is Classification Supervised or Unsupervised?
Classification is an example of a supervised learningalgorithm. Supervised learning is a type of predictive ML that has a known dataset, where the label is the target we are interested in predicting. Examples of labels include name, type, or number.
We can find supervised learning in many applications nowadays.
Here’s an example: Our dataset is composed of images of t-shirts and sweaters. Each is accompanied by a label; in this case, what type of product they are. Our ML model would use previous data to predict the label of new but similar data points. So, if we brought in a new, unidentified image, the model would guess if that image is a t-shirt or a sweater-thus predicting the data point’s label, or in this scenario, which product type.
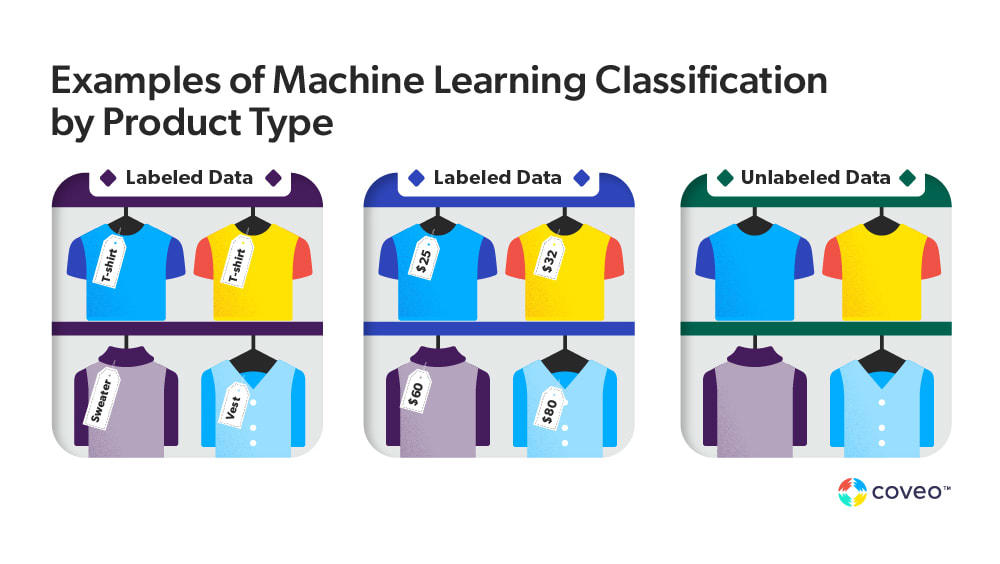
Now, in the figure above we have two types of labeled datasets. One where the labels are numbers (i.e., the price of the products), and one in which the labels are relevant product class (i.e., “t-shirt” and “sweater”). This gives us two types of supervised learning models:
- Regression model: Models that predict a number, such as the price of a garment. (Logistic regression is an exception, as it predicts a binary outcome rather than a number.)
- Classification model: Models that predict a category or class, such as product class. (“T-shirt” or “sweater.”)
Is Clustering Supervised or Unsupervised?
Clustering is an example of an unsupervised learningalgorithm. A dataset with no labels is a dataset with only features and no prediction target. This brings us to unsupervised learning or the wild west of unlabeled datasets.
Let’s go back to the “t-shirts” and “sweaters” examples. The far right box of the above figure shows an unlabeled dataset. If our dataset has no labels, then we have a bunch of pictures of clothing. We don’t know what’s a t-shirt and what’s a sweater. Our model can still tell if two pictures of t-shirts are similar and different from a picture of a sweater. We have to hope that our model can group the images by similarity, even without knowing what each group represents.
Supervised vs Unsupervised Learning: The Future of Machine Learning
Predictably (pun intended), most successes in AI are currently achieved via supervised machine learning. For example, a picture of an engine part is labeled with the part number. A payment event is labeled as a fraud, a customer account is labeled as valuable, and a purchased item is labeled with the price. A sequence in the clickstream is labeled with “yes/no” depending on whether a customer did what you wanted them to do (more on this later!).
By 2022, it’s predicted that the supervised learning technique will remain the ML technique used most by enterprise IT leaders. Yet, unsupervised learning is also a very common type of machine learning algorithm and has surged in usage recently.
Some use unsupervised learning as a prep step for supervised learning. In fact, including unsupervised machine learning as part of the process can benefit an AI project. Unlabeled data doesn’t come with the baggage of human-generated labels. After all, labels may be incorrect and based on erroneous information or bias. After examining 10 of the most-used ML training datasets, a computer science team at MIT found that 3.4% were inaccurate or mislabeled. Sounds like a minuscule number, but depending on the situation can have huge consequences (think self-driving cars).
Clustering vs Classification in Ecommerce
Classification Algorithms in Ecommerce
Classification algorithms use labeled datasets to assign test data into specific categories, such as our “t-shirts” and “sweaters” example.
Our example actually resembles some real-world applications of classification tasks. Consider a classic example of image recognition. Popular image recognition models use image pixels as input, and use this information to predict what the image likely depicts.
The classification method has a lot of potential for ecommerce. Consider this-in 2017, Zalando released its famous fashion MNIST dataset. This dataset came with a training set of 60,000 examples and a test set of 10,000 examples. Every fashion product had pictures shot by professional photographers, showing different product aspects. (Like front and back looks, details, looks with models and in an outfit.)
Each image is associated with a label from 10 classes:
- T-shirt/top
- Trouser
- Pullover
- Dress
- Coat
- Sandal
- Shirt
- Sneaker
- Bag
- Ankle boot
The task is to classify a given image into one of the 10 classes above.
While the above is a great illustration, we can find better uses for classification techniques in ecommerce. Perhaps one of the most relevant is understanding user intent based on clickstream data. In this scenario, a clickstream represents pageviews describing the navigational history of a user session.
In the same spirit of Zalando’s release of the Fashion MNIST dataset, Coveo has also released an anonymized, curated dataset for the ML community. A key application of this large dataset concerns the prediction of intent based on clickstream data.
How Does a Classification Algorithm Determine User Intent?
When a user enters your ecommerce site, wouldn’t you like to know whether they are browsing or are looking to buy? We’re all familiar with this in the physical world. Any great sales associate knows that consumers display clues to their shopping intent: how they move through aisles, the questions they ask, how they dress, etc.
But how do you translate these cues to a digital world?
With a classification algorithm such as naïve Bayes, K-nearest neighbor, decision trees, or random forest you can make predictions and classify customers as motivated buyers or window shoppers. We can try and classify customers – or in this scenario, sessions. We can identify window shoppers by a sequence of actions made by one user during a site visit, which ends if the user is idle for over 30 minutes.
In Coveo’s dataset, we label sessions with six different actions: pageview, detail (user sees product page), add (add product to cart), remove (remove product from cart), purchase (buy a product), click (click on result after performing a search).
For this article’s purpose, we’ll focus on “purchase.” This creates two types of sessions:
- Purchase sessions, where the customer buys an item
- Non-purchase sessions, where the customer doesn’t buy anything
The challenge then becomes classifying a session into one of the two classes above, which is exciting but not easy. For readers interested in learning more about using cutting-edge supervised learning to predict purchase intent with minimal information and signals, the release of our dataset is accompanied by a recent publication in Nature Scientific Reports.
The paper tests two conceptually different approaches: a hand-crafted feature-based classification and a deep learning-based classification. Through extensive benchmarking and optimization, the authors provide state-of-the-art performance on the task at hand. Check it out!
But what if the data structure is unknown, and our goal is to discover it?
Clustering Algorithms in Ecommerce
An unsupervised machine learning technique, clustering involves grouping unlabeled data into multiple clusters via their similarities and dissimilarities. It’s a powerful approach for identifying characteristic features occurring throughout a dataset. It’s particularly useful for applications without a priori knowledge of the data structure because its goal is to discover that structure.

For instance, ML models can cluster similar products (think all shoes). It can also dispatch dissimilar products in different clusters (separating out socks). This can improve the quality of recommendations, or provide relevant results to an out-of-stock query.
We can also apply a clustering method (such as k means clustering) to ecommerce websites’ users. In this scenario, we can identify groups of individuals with similar interests, preferences, or needs.
How Can We Categorize Ecommerce Search Queries Using Clustering?
Quite often, ecommerce retailers use clickstream data to explore users’ browsing behavior. Doing so can reveal interest patterns that allow sites to create truly relevant search experiences.
Another example is grouping search query intent, leading to the “discovery” of relevant groups. Instead of classifying items, grouping search queries lets retailers recognize shopper intent.
In web search, web query intent identification has been a hot topic for some time. By analyzing search behavior, IBM researcher Andrei Broder identified three search intent categories: navigational, informational, and transactional.
Discovering natural clusters of query intents, each representing a distinct ecommerce search task, can lead to customer segmentation and show retailers why people visit ecommerce sites. This could also lead to improving the relevance of their experiences.
To this end, researchers from Walmart applied clustering and came up with a broad taxonomy of ecommerce query intents:
- Shallow Exploration Queries. Short and vague terms used at the start of exploring a product space.
- Targeted Purchase Queries. Users are searching for familiar items that they don’t need more information about.
- Major-Item Shopping Queries. Users are considering a major purchase (i.e., something expensive) and need more details. These items or services are typically limited in scope of choices.
- Minor-Item Shopping Queries. Users are shopping for minor items that aren’t usually very expensive. But because there are many options, they need to do some extra research.
- Hard-Choice Shopping Queries. Users want to deeply explore all of their options before making a decision. This is typical when product constraints are hard to express and multiple products must be carefully evaluated.
If this looks strictly theoretical or abstract, think twice. For example, consider a shopper looking for a major, expensive item. As we’ve seen, she probably requires some serious exploration.
But now imagine for a second the possibilities for your digital shop: how could you design or transform your ecommerce website if you knew which users are interested in major items?
Perhaps they’re looking for social proof, in which case you might consider adopting social proofing techniques to generate confidence in shoppers – and thus boost conversion rates. For instance, leading ecommerce vendors offer social proofing capabilities to showcase customer ratings and reviews on their product pages to provide confidence in the purchasing cycle.
Or maybe the shopper just needs a little nudge. You can leverage product badges that highlight social demand to create impetus and urgency.
Unlock the True Potential of Machine Learning for Ecommerce
The world needs business leaders who understand ML even more and who can embody both business acumen and ML know-how to translate ML into new business value.
You don’t want your enterprise to waste sweat, money, and goodwill on doomed projects. But you can’t know what ML is good for without knowing what it is in the first place (we discuss a number of common misconceptions in this blog post).
This blog is part of a series meant to provide you with a grounding in some core ML concepts. You should have learned from this blog that a statement like, “It’s unsupervised so it doesn’t require training data” is plain wrong.
Leverage your new ML literacy to unlock the full business potential of ML by understanding what ML is, what you can use it for, how to evaluate and explain it, and how to use the right data.