


In early December, we had the chance to remotely attend two major events in the AI community: COLING and NeurIPS.

A 8-bit, Zelda-like version of ourselves (with co-author Federico Bianchi) during the Poster session.
As is usually the case with conferences, both COLING and NeurIPIS provided us the chance to get feedback on our own work (“discovery tags” and hybrid semantics). They also allowed us to take a moment to reflect on broader trends in the field, feel the “temperature” of ideas and approaches, and identify some genuine new problems and perspectives that have arisen.
Given our variety of interests, it is no surprise that we all went crazy exploring different sessions during this very intense week and experienced the well-known conference paradox: attending may feel more tiring than the work that got you there in the first place (well, sort of!).
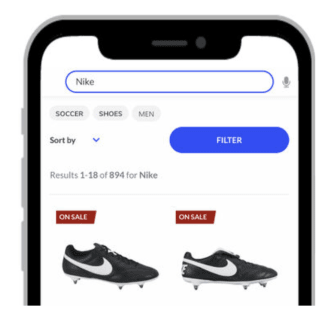
How can we build a mobile-friendly UX to help first-time shoppers refine their search query based on their intent? In this example, “nike” can be refined as “nike soccer” or “nike shoes”. As is the case with everything on eCommerce, tags can be personalized as well.
Without any presumption of completeness, objectivity or consistency, here are six things we liked!
1. NeurIPS: Why abstraction is key and what we’re still missing (Francois Chollet)
Francois is an artificial intelligence researcher at Google. He is prominently known as the creator of the popular neural network API Keras which has no doubt played an important role in driving the rise of Deep Learning initiatives.
In his presentation, Francois highlighted the types of generalization that Deep Learning can and cannot do as well as the settings best-suited for Deep Learning: dense sampling, interpolative. He proposed the use of program synthesis in conjunction with Deep Learning as a means to move towards AI that is data efficient and able to perform human-like abstraction – that is, to easily transfer knowledge from one domain to another.
We find this line of research both theoretically interesting, as it marries the strengths of neuro and symbolic AI, and practically important, as, down the line, many industry problems can be casted as an exercise in program synthesis, e.g., automated data modelling.
2. NeurIPS: Neuro-Symbolic Visual Concept Learning (Jiajun Wu)
Another work in Neuro-Symbolic AI was presented by Jiajun Wu from Stanford – he introduced the ideas behind “The Neuro-Symbolic Concept Learner” (NS-CL).
The paper presents some novel ideas to solve the problem of Visual Question Answering (VQA): given a scene populated by 3D shapes, e.g., a blue cube, a green cylinder, etc., can we train a model that answers a question such as, “Are the red and green objects of the same shape?”. In particular, they present the problem of VQA as one of developing an executable program that is able to learn concepts and semantic parsing without any explicit supervision, as the two components bootstrap off each other.
In addition, the program’s execution is defined to be differentiable, allowing them to exploit the benefits of gradient-based learning. Although the space of concepts is pre-defined (meaning that more work is required to extend these findings to realistic scenery and rich concepts), we found that the model clearly demonstrates the sample efficiency and combinatorial generalization that “hybrid systems” can provide.
Don’t forget to check out DeepMind’s latest take on this!
3. NeurIPS: Bootstrap your own latent (Grill et al.)
Bootstrap your own latent (BYOL) is a new approach proposed by DeepMind to learn dense representations of images in a self-supervised manner. Their work closes the gap between representations learnt via supervised and self-supervised methods, and it shows promising results when evaluated using standard Imagenet benchmarks.
Interestingly, unlike contrastive learning (CL), their proposed method does not require negative training examples to learn good representations – as such, it can be used in cases where explicit labels may be hard to find. Being able to learn and fine-tune representations in a self-supervised manner is critical in downstream tasks where explicit labels may be relatively scarce and expensive, e.g., building representations for product images in rare/niche verticals.
4. NeurIPS: Better Set Representations for Relational Reasoning (Huang et al.)
Sets are a natural representation of a collection of discrete entities, e.g., product tags can be thought of as a set of properties, such as {shoes, men, running}. As such, they are crucial in enabling compositional reasoning. However, current methods for learning set representations in neural networks have limitations associated with decomposing inputs into discrete entities.
This paper introduces an iterative inference step that further refines a set predicted by a neural network through inner-loop optimization. The purpose of this step is to ensure that the predicted set is able to reconstruct a dense representation of the input (as a learnt embedding). The reconstruction is performed symmetrically on all inputs of the set, thereby enforcing permutation invariance (a property of sets).
Our recent work on information retrieval also uses sets to express compositional semantics, and we look forward to incorporating more results from this research agenda in our future work.
5. NeurIPS: Practical Uncertainty Estimation & Out-of-Distribution Robustness in Deep Learning Tutorial (Dustin Tran, Jasper Snoek and Balaji Lakshminarayanan)
Uncertainty and robustness of Machine Learning models certainly pose significant challenges to active research – thankfully, increasingly innovative solutions have been developed recently in order to deal with them. In this tutorial, researchers from Google Brain discuss various cases in which the uncertainty of models can be critical and heavily influence task performance. They also highlight important challenges and lead the audience through recent research works in the space, e.g., the research by Marton Havasi et al.
Many of the challenges mentioned in this tutorial resonated with us – and viable solutions were presented as well, which made this talk particularly insightful for us. For example, at Coveo, while experimenting with AI product categorization in our data-augmentation pipeline, we quickly realized the need to build classifiers robust to out-of-distribution samples: in particular, our models need to know when they don’t know. In this tutorial, two broad categories of approaches that could help us are elaborated in detail, probabilistic ML (usually through Bayesian neural networks, fancier but harder in practice), and ensemble learning (less principled, but very practical).
Finally, to facilitate research in the field and help close the gap between theory and practice, they announce the launch of standardized baselines for uncertainty researchers. They hope that this playground will foster and enhance the research in this field — and we do too.
6. COLING: BERT-based similarity learning for product matching (Tracz et al.)
This paper by giant Polish Ecommerce Allegro.pl addresses the problem of product matching at scale in a marketplace: when different merchants set up different offers for the same product, each using a different label/identifier, how can the system automatically realize which products are identical across different presentations?
As in many cases, finding the answer is both challenging, from a theoretical point of view, and important for the underlying business: understanding products is a prerequisite for price comparison, aggregate product reviews, etc..
The model cleverly re-uses the idea of triplet loss in an Ecommerce scenario: given a triplet containing an offer, a matching product, and a non-matching product, the model is trained to distinguish the matching one from the non-matching one. To adapt to the target domain, a BERT-based fine-tuned model is proposed (ecomBERT), one which leads to the best overall performances against BOW baselines. Architecture aside, the paper is also very interesting in that the authors discuss batch training best practices.
Overall, this paper, and similar papers presented at COLING, confirmed a two-way relation between Ecommerce and Artificial Intelligence. On one hand, Ecommerce use cases are incredibly useful for advancing AI research; on the other, Artificial Intelligence tools are now a fundamental part of building and sustaining any digital shop.
Last international-but-really-Zoom conference of the year: see you in 2021, space cowboys!
Acknowledgments
We wish to thank our co-authors (Jacopo, Ciro, Federico) for helping with previous drafts of this post, and Emily, for continuing to lend us her linguistic touch in 2021.