


“We shape our tools, and then the tools shape us.” – Winston Churchill…
…Or some other famous person. It’s up for debate. Welcome to academia.
Delivering relevance in eCommerce search is easier said than done – even for leading companies. Take the xbox 360 controller search below:
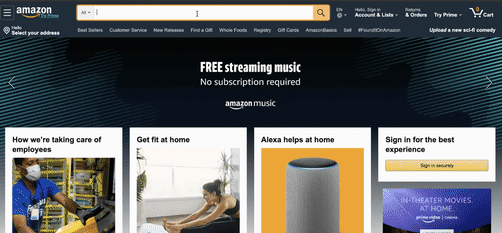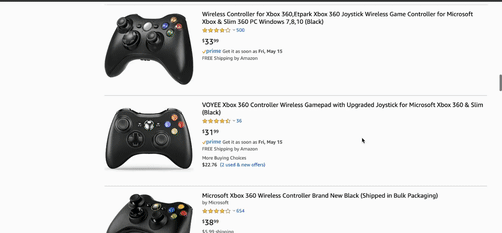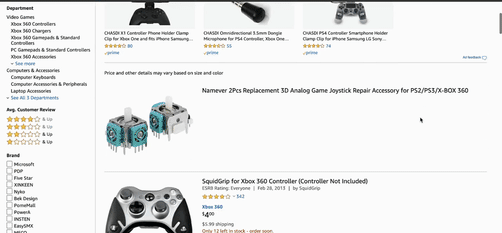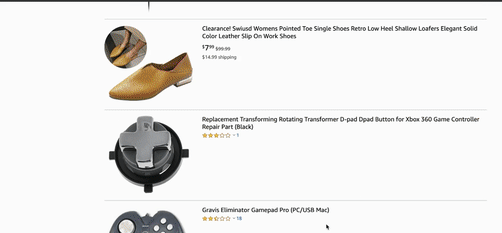
While machine learning is able to put controllers on top at first, a simple “sort by price” re-ranking shows that user intent is misinterpreted by the engine. Controller components and entirely unrelated items are shown, rather than actual controllers themselves – which is what the customer was likely seeking out in this case.
The problem – easy to state, hard to solve – is that machines nowadays are very good at surfacing content based on user actions, but they are so-so at understanding what is semantically relevant in the first place. This is a big problem for modern shops: industry data shows that up to 20% of clicked products are after the first page, with re-ranking occurring in approximately 10% of search sessions.
A common solution is getting UI to come to the rescue: if we can nudge the user, while they’re still typing, to narrow down the result set to a specific category, the final page will look cleaner. For example, in the Amazon search below, the shopper is shown the “Video Games” category:

Today, we build on our latest AI research and show how you can improve any type-ahead system with category suggestions which are AI-driven, that is, those that are able to dynamically change behavior depending on actions in the current session (yes, this means that even unregistered shoppers entirely new to your site will get a personalized experience!).
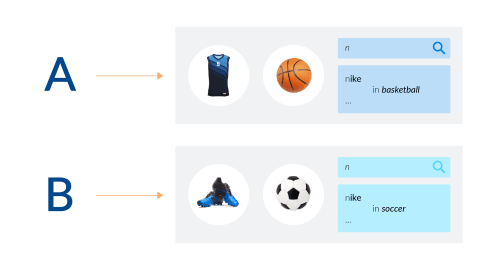
Category prediction for type-ahead can work with general queries such as “nike” by using session information for personalization: different shoppers, different experiences.
If you are wondering what this looks like when you embed it on a real eCommerce site, here’s an example of personalized category suggestions at work on a sample sport apparel shop:
As you can see, the “tennis theme” becomes clearer and clearer during the session, resulting in the shopper getting tennis as the category prediction for nike which is far more relevant than the original prediction of running. And this all occurs in a seamless, streamlined manner.
Today’s guest star is our friend Piero, founding member of Uber AI Labs and father of the awesome deep learning tool Ludwig. This post gives us the chance to re-implement our research with Ludwig and share two cool things at once.
If you’re not quite ready for the nerdy details just yet, learn more about how to personalize from the very first interaction – without massive amounts of data – from the perspective of a non-AI scientist:
For the mighty reader, we share a public repository. And if you want to implement this model on your own website (batteries and data not included!), check out the README to know how to prepare your data to run the code.
Solving the prediction problem
Predicting a category to help shoppers narrow down their search intent is a two-fold challenge: on one hand, we need to learn how to represent candidate queries in a way that is easy for the model to process; on the other hand, we need to learn how to represent in-session intent. Perfect personalization can only be achieved by combining linguistic behavior with product interaction – neither is sufficient on its own.
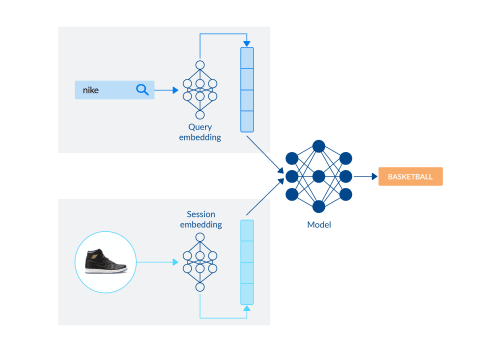
At its core, category prediction combines dense representation of the candidate suggestion (“nike”) with a dense representation of the shopper session (interaction with basketball shoes) to produce a prediction (basketball).
Compared to existing approaches, we introduce three important innovations:
1.) In-session personalization
Session vectors influence the prediction, allowing for a personalized experience to be delivered, even to non-recurrent users entirely new to your site. To represent session intent, we resort to product embeddings (introduced here) for the products in the current session, and then take average pooling to represent session intent.
2.) Search2Prod2Vec
We represent candidate queries with a novel approach: Search2Prod2Vec (our “small-data” variant of Search2Vec designed for websites where many sessions do not have queries.) In particular, if you take shoppers’ clicks after a query (e.g. nike shoes) as a “pointing signal”, you can represent nike shoes as the weighted average of the embeddings of the products clicked.
3.) Path prediction
We conceptualize category prediction as a path prediction, not a simple classification problem. In other words, we are going to exploit the tree-like structure of catalogues to make the model aware that predicting sport/basketball vs. sport/soccer is not the same as sport/basketball vs. apparel/pants. In the first case, the target leaves share their parent in the product tree, in the second they don’t.
[NERD NOTE]: We are leveraging catalog structure as an inductive bias to improve model performance.
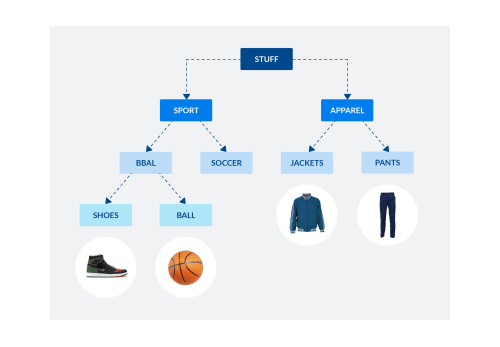
Since products naturally form a tree (i.e. a taxonomy), we should be able to predict entire paths, not just categories as mutually exclusive buckets.
While path prediction is not new per se (for a customer care example, see COTA from Uber), we are the first to present this model in the eCommerce industry.
Finally, it’s easy to see that if you’re not predicting just a category, but also the path through the catalog that will follow, it becomes natural to ask the question of when to stop. Should we nudge the user into sport and leave them be, or nudge them further into sport/basketball specifically?
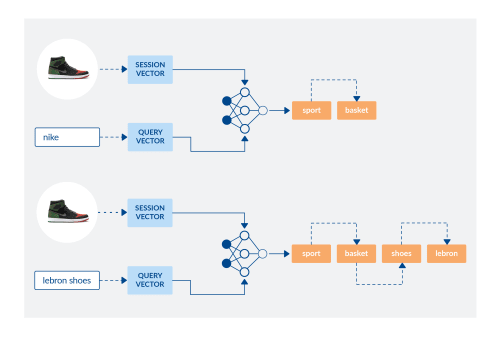
We expect the model to predict deeper paths when session and linguistic data are very specific (right, bottom) and resort to general facets when unsure (right, top).
Putting all these new ideas together and testing them out requires a ton of custom deep learning code: or does it? With the help of our guest star Piero, we built a slightly simplified version of our original model in literally a few lines of code.
Ludwig to the rescue: a no-code framework for prototyping
Ludwig is a deep learning toolbox that “allows users to train and test deep learning models without the need to write code”. Ludwig’s father is Piero Molino, who provided us with a super-duper shortcut to build the bulk of our cutting-edge model with very little code.
The category prediction model we are going to build is an encoder-decoder model. In the encoding part, we use the popular wide & deep approach to concatenate textual features (a dense representation of the candidate queries) and behavioral features (an average of the product embeddings for the current session); in the decoding part, we use an LSTM to “unroll” the path, one taxonomy node at a time, e.g. sport > soccer > shoes.
Ludwig is easy to use – to provide a complete, “stateless” and self-contained pipeline, we wrap prod2vec training, dataset preparation and Ludwig APIs in a Luigi pipeline. The magic happens in the model definition, where a simple dictionary with options is passed to initialize the class:
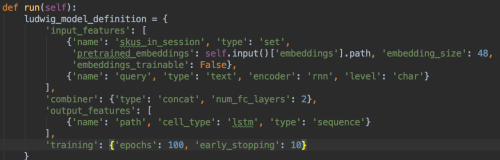
Ludwig allows easy declarative definition of complex models: the dictionary above is what is needed to combine session vectors with a query model (char-based language model) and predict a taxonomy path!
The configuration object above is sufficient (provided there is some convenient data piping and pre-processing orchestrated in a consistent way through Luigi) to tell Ludwig which architecture we need so that we can train and test it over our dataset with no additional setup. Once that is done, we store statistics and predictions in local json files for human inspection.
If you run the code in the shared repository, you will be able to supply your own input products/queries and easily visualize model predictions:
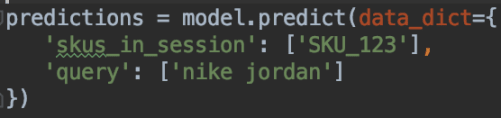
Ludwig just saved us a ton of time in testing our ideas. While it was mainly designed as a “no code” tool to get deep-learning powered predictions, its clean APIs allow experienced programmers to explore novel research ideas in a breeze – leaving more time to focus on end-to-end program solving rather than low-level details when prototyping.
One size does not fit all: making humans and machines work together
If you have followed us up to this point (congrats, by the way!), you should have a model that (1) takes session & query data as input and (2) produces a taxonomy path as output. Consider the two scenarios below:
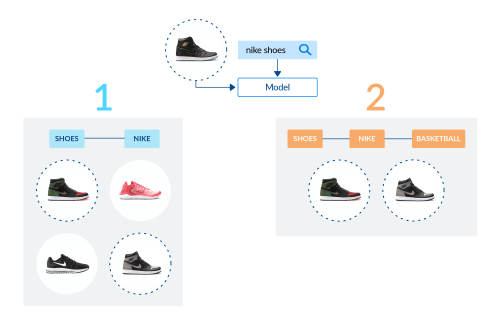
Two prediction scenarios for our path prediction: In case 1, we predict a conservative path, with some basketball and non-basketball shoes; In case 2, we aggressively narrow down the result set to just two items. What is the best strategy?
Given a basketball-themed session and the somewhat vague query “nike shoes”, our model can in principle make two decisions:
- a “conservative” prediction, shoes > nike: the model helps the user focus on a subset of shoes for the specified brand but does not aggressively personalize towards the theme of the session;
- an “aggressive” prediction: shoes > nike > basketball: the model nudges the user into a very specific section of the catalog, by placing “a bet” on a specific sport interest.
The trade-off resembles the usual precision-recall tradeoff in search engines, and different clients may have different sensibilities about which strategy for prediction is optimal. Fashion shops tend to prefer clean, minimal result sets (i.e. give us more precision – they say). DIY shops prefer more varied search pages, even if this generates more noise (i.e. give us more recall – they say).
Since no size fits all, we augment our model with a “decision module”. After a path is generated by the encoder-decoder architecture, the predicted nodes are sent to the decision module in sequential order based on the confidence score calculated for each. If the score is above a threshold, the node is added to the final path returned to the user. If it falls below that threshold, it is not added.
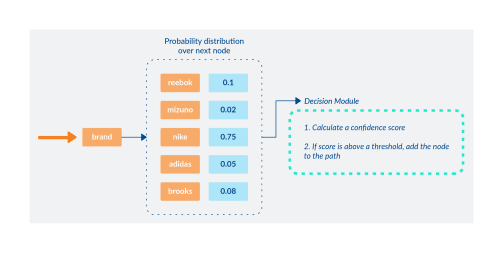
After the neural network produces a taxonomy path, we ask a decision module to evaluate at each node how confident the model is about going deeper and deeper in the product tree: if the model is confident enough, the new node is added to the path, otherwise the path is stopped and shown to the user.
The problem of “tuning a neural network” to work for the different needs of fashion and DIY clients became the much simpler problem of tuning a confidence threshold: the lower the threshold, the more geared towards precision the model will be. To gain a more concrete understanding of model behavior, it is helpful to observe it in the context of real eCommerce data.
For example, the picture below compares how the model adjusts the prediction for “nike shoes” given (1) different product interactions during in the session (no product, running shoes, basketball shoes) and (2) different thresholds of “confidence”.
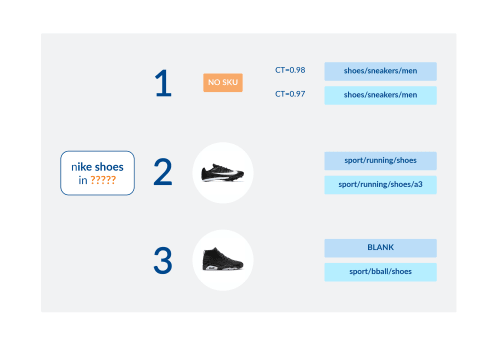
Three prediction examples with different confidence thresholds (CT) for the query “nike shoes for man”. In one example (session #1), there are no product interactions – predictions are mostly guided by popular items in the catalog. In the other two sample sessions (session #2 and session #3), the model picks up the sport-theme, adjusting its “aggressiveness” based on CT.
Even when the model is not perfect (running shoes in session #2 are “a7” not “a3”) the model is still very good at guessing where to direct the typing user with very little information.
Where to go next
“The simple truth is that companies can achieve the largest boosts in performance when humans and machines work together as allies, not adversaries, in order to take advantage of each other’s complementary strengths.” –
Paul R. Daugherty
As promised, we presented two cool things in one post: a new way to solve category prediction for type-ahead systems and an end-to-end deep learning implementation leveraging the abstraction offered by Ludwig. We know, however, that the devil is in the detail sometimes – and there are a lot of details we glossed over for the sake of brevity. If you’d like to get the full scientific story, with extensive benchmarks, references and experiments, read our paper and let us know what you think.
Technically, the best thing about the proposed method is that it is a blueprint for more experiments within and across use cases. On one hand, the encoder-decoder framework can easily be adapted to represent user intent and search queries in other ways – want to try BERT? It’s so easy! On the other hand, the very same model can be used with no changes to tackle, for example, query scoping – given the structure of a search query, can we map it to structured data attributes in order to pre-filter the results automatically and improve precision as a result?
Finally, it is worth reflecting on the interplay between human and machine intelligence. For many businesses, the rise of AI has given way to skepticism regarding neural network solutions and a desire to continue to employ traditional methods. McKinsey aptly captured this sentiment:
“More familiar, traditional decision-making processes will be easier to build for a particular purpose and will also be more transparent. Traditional approaches include handcrafted models such as decision trees or logistic-regression models.”
Our methodology dares to dream a different dream: we retain the accuracy and flexibility of neural networks without giving up human intervention, in a principled, easy-to-understand way.
See you, space cowboys
If you want to learn more, don’t forget to follow us on LinkedIn and stay tuned for our next exciting work: Coveo R&D is hiring – check out our open positions if you like to join our quest of revolutionizing search with AI.
Acknowledgements
Thanks to our guest star Piero, starring as himself – picking up Ludwig was really a lot of fun! Thanks to our paper co-author Marie Beaulieu for her patience and product insights; finally thanks to Emily for the usual “English touch”.
————
APPENDIX: retro-fit your type-ahead API to use dynamic category prediction
Consider a fairly typical information flow for type-ahead systems in a sports apparel shop:
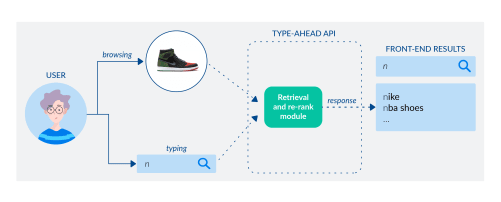
High-level flow of a type-ahead API: <context, prefix> as input, a list of candidate suggestions as output.
As the user starts typing, say, the letter n, the session context (that is, the products the shopper interacted with in the session) and the prefix n are sent to the type-ahead API. The service retrieves candidates (e.g. nike, nba jersey, nba shoes, lebron shoes, etc.) and re-ranks them (first nike, then nba shoes, etc.) with some logic to produce a final list that is returned back to the shopper in the dropdown menu. To improve upon this with our personalized model, we can keep the basic API the same (internally) and wrap it around a lightweight structure:
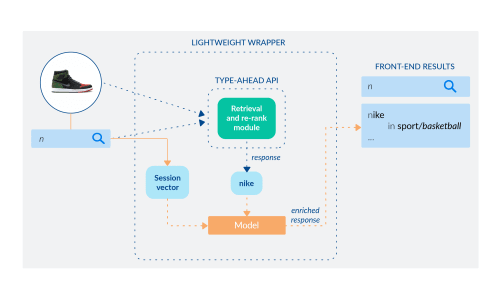
A modified type-ahead API: <context, prefix> as input, candidate suggestions + category prediction as output.
We still send the <context, prefix> as input to the existent API and get the list of suggestions (e.g. nike for prefix n); then, we send a vector representing the shopper session and the top query suggestion (i.e. nike) to our model (in red) and ask it to predict a personalized category based on product interactions up to that point; the response is enriched with the category and the final dropdown menu will display: nike in basketball as required. The fact that this model can be implemented on top of existing infrastructure, neural or traditional, makes it a perfect add-on for any eCommerce site.