

In enterprise search, “recall” measures how well a search engine is able to find and return every possible item that could be of interest to a particular user.
Let’s say a user searches for “iconic sci-fi movies” on a streaming platform. If there are 15 movies that would qualify as “iconic sci-fi movies”, but only 10 are returned in the results, then we would say that search engine has a recall of ~67%. Essentially, recall is measured as a percentage of all relevant data and, therefore, it is only as good as the quality of your index.

In the case of our sci-fi buff, they are interacting with a search engine whose index is rather lackluster, as the search engine doesn’t return five movies relevant to the query in question even though those five movies are available. This is a problem for the streaming service in this scenario, especially if one of those missing movies is the one that their sci-fi enthusiast was most hoping to watch.
This is why it is essential to get all the content you have into the search engine. If you don’t, nothing else matters, as that content and all the value it holds is lost. And this idea of bringing everything together is particularly important when you have valuable stores of on-premises content. Without that content available, you’ll feel like you’re only tapping partial institutional memory – and in some cases, you simply can’t afford to have incomplete information.
If this sounds like a problem you’ve been facing, well, and this one is for the sci-fi buffs reading this, “Get ready for a surprise!”
Most Content Storage is a Hybrid – a bit of cloud, a bit of on-premises
Most organizations are challenged by having:
1.) A rapidly expanding data footprint
AND
2.) Countless data storage locations: multiple instances, subsidiaries, and on-premises/cloud/hybrid environments
The reality of the situation is that there are relatively few enterprises out there that are truly all-in on cloud. Despite the fact that 83% of enterprise workloads are expected to be in the cloud by the end of the year, it is likely that many of those organizations, and certainly the remaining 17%, are still reliant on on-premises hosting of business applications in some capacity. Culture, security concerns, and governance mandates are typically the leading factors that keep applications and data on-premises.

This is happening alongside the gravitational pull that keeps many applications on-premises – namely, the thought that it will be painstakingly difficult to migrate them to the cloud. If they work well enough at a good enough cost, then there’s no business case to move them, right? Let us suggest that you take a vacation from that way of thinking, but first, let’s start by addressing some common difficulties.
The Challenges of Indexing On-Premises Content
It can be very difficult to get silos to work in tandem because they were never designed to do so. Instead, they were designed for a world where fragmentation of systems and related processes was the norm. Given that they were never meant to speak to one another, it is hard to move them to start communicating now that constant data exchange has become essential to meeting the expectations of your digital users.
Unfortunately, many cloud solutions do not make it easy to integrate with internal systems. It’s difficult to index the data, and trying to secure it tends to only worsen your migration-induced migraine. Traditional infrastructure is almost always siloed and incompatible, requiring you to put in more time and effort to integrate across systems. It’s no wonder that 78% of enterprises cited a lack of resources & expertise as their top challenge in moving to the cloud.

Although many cloud solutions complicate the integration process, that doesn’t mean they all do. In fact, with the right solution, that process can be painless and quite simple. Remember that surprise we told you to get ready for?
A New Search Crawler for Your On-Premises Content
If your security policies don’t allow an inbound port in your firewall to access on-premises content, and if your resources cannot support significant development efforts, then the Coveo Crawling Module is the answer you’ve been looking for.
It runs outside of Coveo, behind the firewall, and is integrated with the customer’s environment. This enables it to pull content from your on-premises systems and push it to the Coveo Cloud index. In other words, it makes all your content searchable and findable without you ever needing to give away the keys to the realm beyond the firewall.
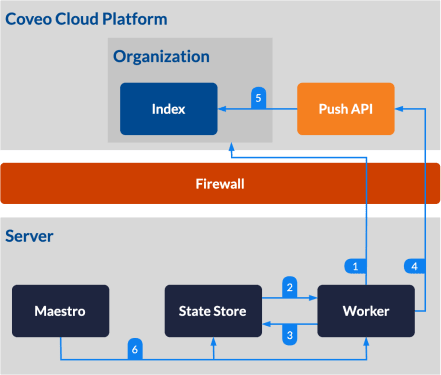
The Coveo On-Premises Crawling Module indexing workflow
In doing so, it offers connectivity to common systems like Atlassian’s Jira and Confluence, as well as content management systems like SharePoint and OpenText Content Server.
The best part is that implementing it is not nearly as difficult as you might think it is.
Simplified Installations and a Configurable Setup
Setting up the basic crawlers requires you to follow these simple steps:
- Step 1: Download a single, self-contained application.
That’s it.
That single application includes everything you need to manage, execute, and monitor a content store.
Once the Crawling Module is deployed on your server, all communications are outbound – no inbound ports to your secured enterprise system are required. Changes resulting from update operations are picked up by the Crawling Module, and it then indexes those changes so that the content appearing in your search results reflects your actual on-premises content.
You can manage and administer an on-premises source fed by the Crawling Module just like you would a cloud content source, meaning that you’ll have control over updates, privileges, and configurations. This allows for a seamless configuration of on-premises secured sources, including those that rely on Active Directory for user access and provisioning.
Crawl, Walk, Run
You need a single source of truth for your corporate knowledge and a complete view of your customer data. Only when you have full awareness of your available content and a customer’s needs can you provide them with what they are actually looking for and meet their expectations. Siloed systems hinder your ability to provide a truly exceptional digital experience for your customers.
A search platform that works seamlessly regardless of the specific functions it serves or the IT environment it runs across – on-premises, private, or public cloud – is what can help you move past the constraints of traditional on-premises offerings. It will allow you to attain the search & retrieval capabilities that you’ve been seeking and that your customers already expect to be available.

Such a platform provides access to all information from across the enterprise, even if it’s traditionally siloed data contained in a database or file share, and makes it all available in a single, unified index.
This is the only way to achieve the speed and agility required to move as fast as the markets around us. Start crawling all your content and you’ll quickly see just how fast your business can run. Who knows, maybe you’ll even end up leading the pack.
Download the latest Coveo Crawling Module today and get ready to kick things into high gear. If you have any questions about availability, let us know.
And for our sci-fi buffs – “We hope you enjoyed the ride.”