

In some previous installments of this exciting series, we described – at length – the super cool concept of product vectors (or “embeddings”), and how they can be used to achieve personalization at scale. For those of you connecting just now, here’s what you need to know about us to catch up – we can represent an Ecommerce catalog as a space, in which similar products are close and somewhat unrelated products are further apart from each other.
If you’re not quite ready for the nerdy details just yet, learn more about how to personalize from the very first interaction – without massive amounts of data – from the perspective of a non-AI scientist:
The animation below illustrates the product space for one of our partnering shops – each point is a product, and the color reflects the category of that product. The fact that products with the same color tend to cluster together (all running items are in violet, soccer is light blue etc.) reveals that the machine responsible for building this space (using user-product interactions) was able to capture product affinity fairly well.

However, the devil is in the details. If you have a space, you can take a look at a product’s surroundings. Sneakers, which are very popular products, are typically surrounded by semantically similar items, such as other sneakers. More niche purchases are surrounded by a noisy cloud of related and not-so-related products – in our space, GPS watches are not only close to watches but also a GoPro accessory and scuba diving equipment:
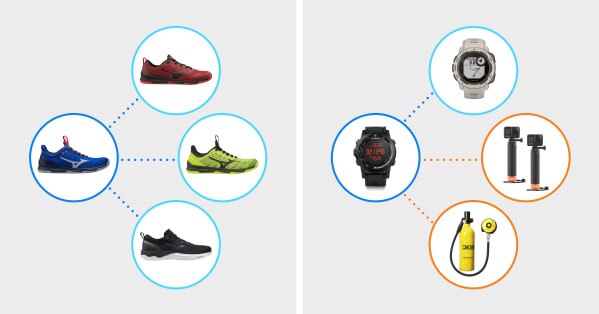
In other words, due to the nature of training, popular products have good quality vectors associated with them – you’ll find products that are actually similar. Less popular products have far worse embeddings. And, of course, new products have no embeddings at all, as online users haven’t interacted with them. That means there is no input that the machine can use to learn to identify a product and its semantic surroundings.
Now that you’ve seen just how good popular products have it when it comes to being surrounded by good company, you may be wondering – is it possible to create vectors of a similar quality for rare and new products? This is the “cold start embeddings” challenge and, yes, we are going to show how to solve it in a scalable way, using a multi-tenant provider such as Coveo.
NERD NOTE: this work is based on our research paper “The Embeddings that Came in From the Cold”, presented at the world premiere conference on recommender systems – RecSys 2020 – together with peers from Etsy, Amazon and Netflix. The research paper was co-authored with Federico, a world-class expert in embeddings and, apparently, sports apparel! If you are looking for the original slide deck, you can find it here.

Catalog Data To The Rescue
If training a standard prod2vec model with shopping interactions creates the “cold start” challenge, we need to look beyond user behavior to solve it.

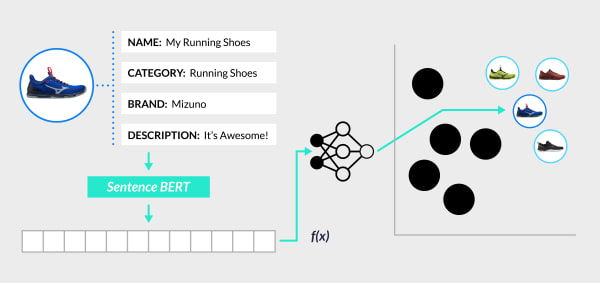
Thankfully, we don’t have to look that far, as we can leverage information in the form of text and image meta-data contained in the product catalog. Take our pair of popular sneakers again – let’s look at how they may be represented in the catalog of a sports apparel shop:

We know that popular products have high quality embeddings, i.e. their position in the space is near perfect. Moreover, we also know that even though less popular products don’t have good embeddings, they do have good quality catalog meta-data. And products similar to those uncommon products should have similar catalog meta-data, regardless of their popularity.
The key insight of our method is the following: if we could learn the relationship between meta-data in the catalog and the position in the space for popular products, we could use that mapping to determine where less popular products with similar meta-data, like our GPS watch, lie in the product space. And as a result, we could also determine what products would actually be associated with them.
Let’s look at the training phase in greater detail. For popular products only, we train a multi-input encoder (concatenating BERT-based representations of product data) to learn the mapping between meta-data and the target space:
Once the mapping is learned, we apply it to less popular and new products, so that their vector in the space is no longer the one calculated through sparse shopping interactions, but rather a “synthetic” vector that has been produced by the machine from their catalog data:
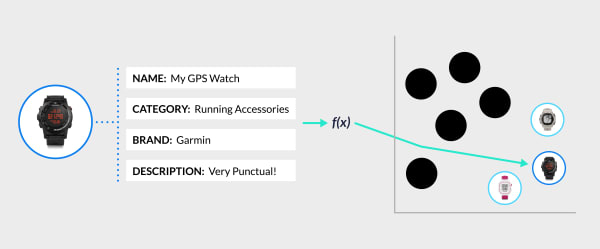
The GPS watch is a less popular product, so its embedding is calculated not from behavioral data, but from the content of the catalog. As a result the watch gets mapped into the appropriate region of the product space – that which contains other watches.
Does it really work?
At Coveo, we proudly power recommendations for hundreds of customers, ranging from medium businesses to Fortune 500 companies. A crucial test for all our innovation is robustness, as our machine learning models need to be able to produce tangible values in very different business scenarios and training regimes. To test our “synthetic embeddings” strategy, we sample three clients from our network, differing in traffic, catalog size, and vertical:
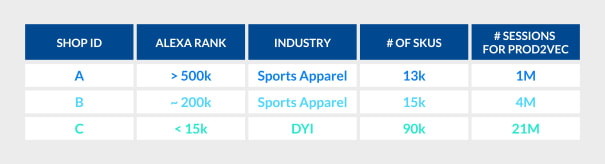
For all of them, we evaluate our embeddings through a standard Next Event Prediction task with a vanilla LSTM: given a shopping session with product interactions P1, P2… Pn, can the model reliably predict what Pn+1 is going to be? As a baseline, we compare a pure behavioral prod2vec space (“ORIGINAL”) vs. a new space (“MIXED”), obtained by replacing/adding content-based vectors for rare/new products. Since rare products are, well, rare, we keep track of the overall precision (NDCG@10) of the models as well as the performance with particular respect to cold start case.

Across all shops, the proposed method upholds the same global accuracy, but it is significantly better (>10x) than the behavioral model for the cold start scenario.
On the Importance of Being “Less Wrong”
Together with a pure quantitative analysis, customer interviews highlight the importance of being “at least reasonable” when not entirely right. In particular, hit-or-miss measures are good at capturing global patterns of accuracy, but they fail to account for some important aspects of the final user experience. Consider the two wrong predictions below:
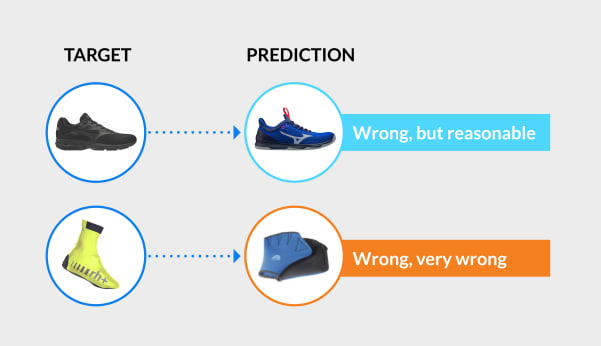
In the first case, the suggested item is not what the actual shopper intended to find, but it’s reasonably close; in the second, we are not just wrong but terribly wrong.
Even though perfect mind-reading is impossible – who knows, maybe in the future we’ll recant this statement – reasonable suggestions are powerful in shaping the customer experience, and they are the result of robust product spaces. At a time when bounce rates are sky high, completely missing the mark when suggesting products to shoppers may actually prompt them to leave the site or discard future recommendations entirely. To test the robustness of the proposed methods, we re-run our two models on the testing set and keep track of the average cosine distance between prediction and target for every wrong prediction in the “cold start” scenario (lower values are better, as it means the two items are closer in the latent space):
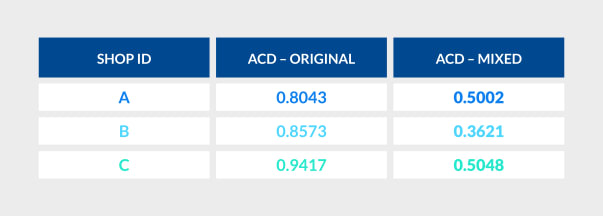
Yet again, for all three shops, the proposed method significantly outperformed the baseline, revealing that taking special care to account for unpopular/rare and new items is likely to produce more robust recommendations overall.
See you, space cowboys
In this blog post, we presented a scalable solution to the “cold embeddings” problem in Ecommerce and benchmarked its accuracy across a variety of deployment scenarios. Notably, our method does not require replacing existing training infrastructure or changing interfaces between application layers, whereas many other solutions in the literature do.
Any downstream system using product embeddings will continue to work just as well (or better!) with the new vectors. Moreover, content-based embeddings base their accuracy on other dense representations, which can be improved upon/added to (e.g. image vectors) independently of the rest of the training/serving layer.
For the visually inclined, we’d like to remind you that cold-start embeddings have been brought to you by an industry-academia think tank – the “teaser video” for RecSys 2020 was animated by Ciro and can be viewed below:
If you want to learn more about Coveo, follow us on LinkedIn, talk to a Coveo expert, or check our open positions.
And if you want to learn more about everything we’re doing to make personalization possible in the world of Ecommerce, check out our solution page.
Acknowledgements
Thanks to our co-author Federico, for the usual creative touch, and to Emily, for the usual linguistic sophistication.