

Federated search is a critical first step for information retrieval and knowledge management. But it alone likely won’t be enough for most organizations’ enterprise search needs. Let’s break it down.
Traditional search required your employees to log into different disparate databases to find those nuggets of knowledge they needed. That meant knowing which silo to look at, not to mention passwords and logins for all the multiple platforms. Enter federated search tools – which use a single search index to query across multiple data sources.
This seemed like the perfect solution as organizations grappled with content across multiple sources – cloud-based and on-prem and ecosystems of record. Yet what the Covid-19 “pause” revealed (and what many IT leaders have known for a while) is that federated search is not enough.
Here’s what you need to know to truly meet your users’ expectations for a truly digital workplace .
What Is Federated Search?
First, the basics: Federated search retrieves information from a variety of sources via a search application built on top of search engine(s). One user makes a single query and the federated search engine simultaneously searches multiple, usually disparate databases and ecosystems of record, returning content from all sources for presentation in one user interface to the user.
In complex organizations with thousands of sources in the cloud and on-premise, this is invaluable.
In addition, most federated search engines can also pass along the users’ credentials in the search query. For example, a manager at a tax advisory firm may want to find previous years’ tax returns – but that manager should not have credentials to access other firms’ forms and information resources. By enabling the search engine to pass the end user credentials in an authenticated user setting, the security model of the content is still respected.
What are the Types Of Federated Search?
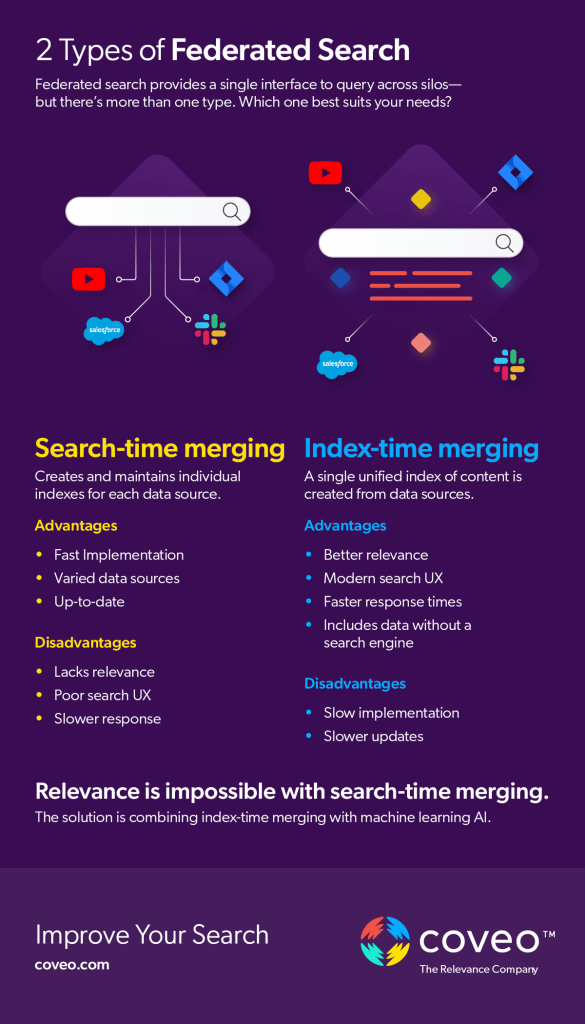
There are two distinct approaches to federated search: search-time merging and index-time merging.
- Search time merging (also known as query-time merging) requires a query generator that sends out a query to multiple search engines of each data source. The query generator in turn, produces an aggregate list of search results. This solution’s advantages in simplicity need to be weighed carefully with the costs to speed. Because each index is maintained and searched separately, the response time can be significantly slower than the real-time expectations of users.
- Index-time merging is a type of federated search system that creates a single, unified index of all content from all data sources, that is searched at one time. The effort to implement an index-time merging solution is high – but its enhanced functionality is worth it for user experience when compared to query-time merging. Most tech-savvy organizations end up choosing an index-time merging solution solely for that reason.
Advantages of Search-Time Merging:
- Speed of implementation: Search-time merging solutions are simple and quick to implement. Without having to set up a central index, you can quickly get this method set up.
- Difference in data sources: One of the reasons why it is so quick to implement is that the indices do not have to be standardized. If your dataset for one index is in one format, and the other is another, it is not an issue for a search-time merging solution.
- Always up-to-date: Because each individual index is always up-to-date, the search-time merging federated search engine does not have to consistently go back and index the source to make sure the content and results are up to date.
Disadvantages of Search-Time Merging
- Poor search relevance: Since each search engine creates its own relevance, ranking results across all content sources is near impossible, so most organizations end up returning results according to a deterministic attribute such as date, price, alphabetical, etc. For example, in some complex manufacturing settings, users may search by any number of product synonyms or the SKU itself. Catalog maintenance and taxonomy management is much more complex with federated search engines. And with the sheer amount of tuning required, most digital experiences with federated search will still fall short.
- Poor search user experience (UX): Most people assume that the search experience only involves the search box and results page – but users today expect much more than that. Taking the prior example a step further, think of the best search experience you’ve had and all of the different capabilities that requires: autocomplete, query suggestions, filtering and faceting … the list goes on. In a federated search scenario, unless all “federates” support each of those capabilities your federated search box won’t be able to either. The search UX is incredibly important to users; search is what makes our lives easier and often many users’ first reflex (thanks, Google!). In a web search capacity, conversion rates rise by up to 5X when search is optimized. The bottom line: the search user experience is too important to overlook.
- Slow response times: Response times become an issue when the response for the results automatically defaults to the slowest search source. This is primarily an issue with search-time merging, as each index needs to be searched and maintained separately.
Advantages of Index-Time Merging
- Better relevance: If you are able to bring everything under one roof, you can at least manually (which will be quite painful) tune results for relevance. This is slightly less painful with an index-time merging solution.
- Modern search user experience: In a query-time merging solution, the weakest link of your search experience becomes the search experience. So if one data source lacks the ability to use facets or filtering, filters and facets won’t be there in your federated search solution. Index-time merging only takes the content. and then filtering, faceting and other capabilities of the search user experience are built on top, ensuring a best-in-class search experience.
- Faster response times: Is it easier to find a needle in one haystack or multiple haystacks? Obviously, the one. Therefore, because everything is centralized in an index, it can return results faster searching one index as opposed to searching multiple with a query-time merging solution.
- Inclusion of data that does not have a search engine: Even in today’s day and age, not all content has a search engine – and that makes it even more important to bring into a central index.
Disadvantages of Index-Time Merging
- Speed of implementation: Index-time merging solutions take a longer time to implement. Creating the index, navigating connectors, ensuring the single data model is set up – it’s a time and resource investment. If you try to build this yourself, this becomes a much bigger problem. If you can buy an established product with connectors and a platform that will normalize data across sources, you can avoid this disadvantage.
- (Potentially) slower update times: There may be a delay in updating the content in your central index from the content sources. This is why you need a solution with connectors. Connectors can have an incremental update feature so every five to ten minutes, you can see incremental updates of changes. Think quick updates all of the time – but this is very difficult to build yourself.
What are The Challenges With Federated Search?
Users today expect more than federated search. They expect relevance.
Why? As knowledge workers and consumers, we have been trained by digital first-companies, from the most engaging ecommerce site to our favorite streaming sites, to have the most relevant information queued up front and center.
But, as stated above, relevance is near impossible with query-time searches, and while possible, highly labor intensive with index-time searches. There is a solution to reduce the labor in index-time searches — combining index-time merging with artificial intelligence — more specifically, machine learning.
Machine learning analyzes user behavior signals and the content types themselves, to better understand user intent and context.
To understand how Coveo approaches this, request a demo.
How to Go Beyond Federated Search?
The Coveo Relevance Maturity Model lays out a clear framework for understanding the maturity of your organization’s digital relevance and enterprise search. While index-time merging is a step above siloed search where each source is searched separately, it still fails to meet user expectations for predictive, intelligent digital experiences. As you move up the CRMM, the value to the business multiples.
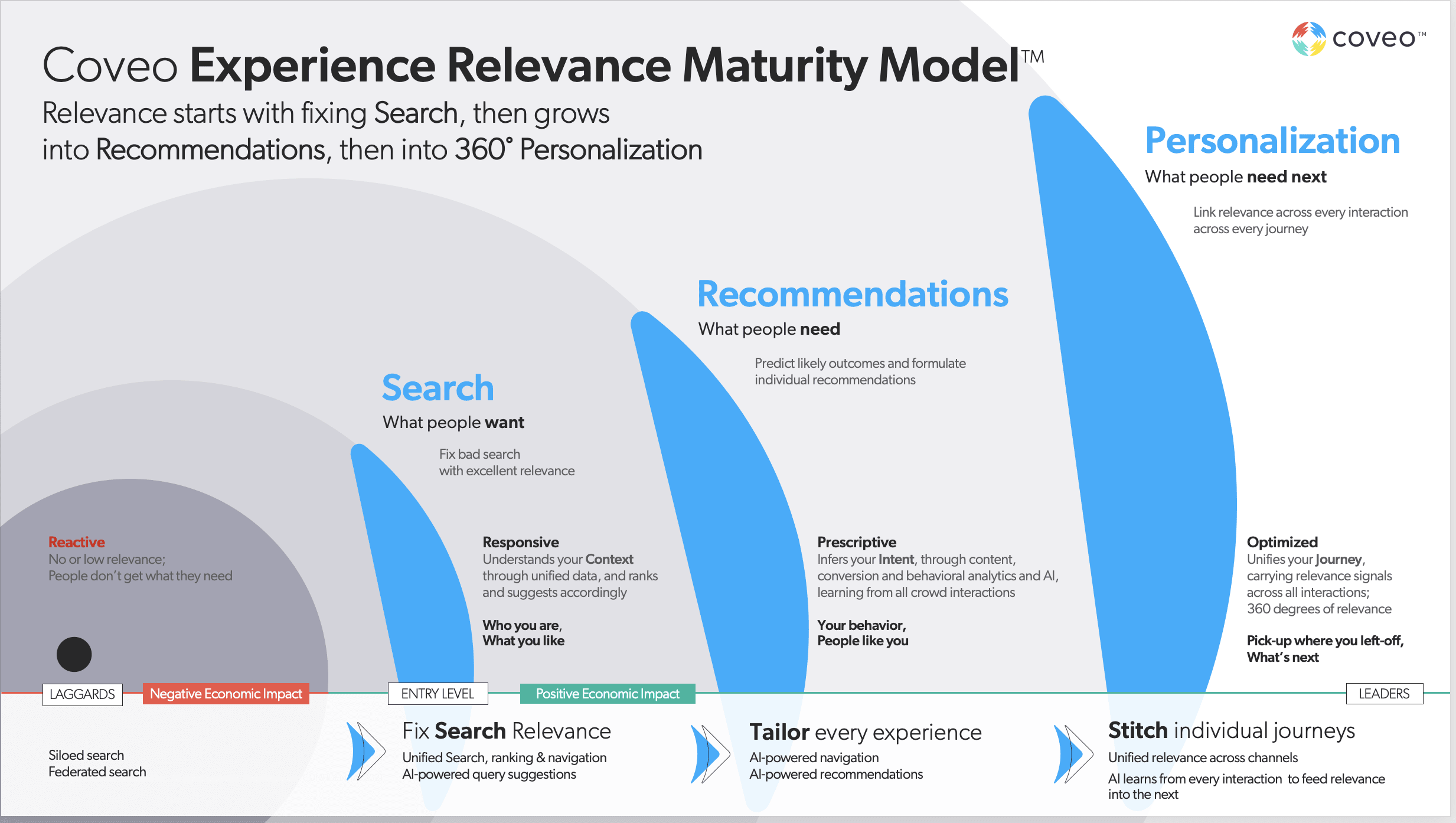
Maturity Level: Reactive
- Siloed search: Information lives in separate silos and needs to be pursued and evaluated by the person searching. Lots of work, poor results.
- Federated search: One search that spans silos, but the results are still not ranked against each other, and the person searching has to do the work of determining relevance.
- Digital experiences like websites, intranets, chatbots, and so on are static, offering one universal experience for everyone — one-size-fits-nobody.
- No tailoring for the individual who is interacting with the experience.
Maturity Level: Responsive
- Give people what’s helpful to them.
- Make search easy: One place to search, with useful features like query auto-completion and query suggestions.
- The experience considers who you are and what you like.
- The experience considers what has worked for other people like you in the past.
- Results are unified, and ranked against each other, based on relevance.
Maturity Level: Prescriptive
In addition to relevant, satisfying search:
- Prescribe what people need
- Predict outcomes and formulate individual recommendations
- Tailor every experience, including AI-powered navigation
Maturity Level: Optimized
In addition to relevant, satisfying search and tailored, contextually useful recommendations:
- Prescribe what people need next
- Link relevance across every interaction of every journey
- Pick up where you left off, across every channel and platform.
Ready to take the next step? Discover how you can have relevant search on day one.